
为何要有索引?
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
索引类型
mysql索引类型 primary,normal,unique,full text的区别是什么?
primar:主键索引 它是一种特殊的唯一索引,不允许有空值。
normal:表示普通索引
unique:表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号用作索引时,可设置为unique
full textl: 表示 全文搜索的索引。 FULLTEXT 用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
总结,索引的类别由建立索引的字段内容特性来决定,通常normal最常见。
索引方法
MySQL目前主要有以下几种索引方法:B-Tree,Hash,R-Tree。
一、B-Tree
B-Tree是最常见的索引类型,所有值(被索引的列)都是排过序的,每个叶节点到跟节点距离相等。所以B-Tree适合用来查找某一范围内的数据,而且可以直接支持数据排序(ORDER BY)B-Tree在MyISAM里的形式和Innodb稍有不同:MyISAM表数据文件和索引文件是分离的,索引文件仅保存数据记录的磁盘地址InnoDB表数据文件本身就是主索引,叶节点data域保存了完整的数据记录
二、Hash索引
hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
1.仅支持"=","IN"和"<=>"精确查询,不能使用范围查询:由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
2.不支持排序:由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算
3.在任何时候都不能避免表扫描:由于Hash索引比较的是进行Hash运算之后的Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果
4.检索效率高,索引的检索可以一次定位,不像B-Tree索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以Hash索引的查询效率要远高于B-Tree索引
5.只有Memory引擎支持显式的Hash索引,但是它的Hash是nonunique的,冲突太多时也会影响查找性能。Memory引擎默认的索引类型即是Hash索引,虽然它也支持B-Tree索引
补充一下HASH索引的过程,顺便解释下上面的第4,5条:
当我们为某一列或某几列建立hash索引时(目前就只有MEMORY引擎显式地支持这种索引),会在硬盘上生成类似如下的文件:
| hash值 | 存储地址 |
| 1db54bc745a1 | 77#45b5 |
| 4bca452157d4 | 76#4556,77#45cc… |
…
hash值即为通过特定算法由指定列数据计算出来,磁盘地址即为所在数据行存储在硬盘上的地址(也有可能是其他存储地址,其实MEMORY会将hash表导入内存)。
这样,当我们进行WHERE age = 18 时,会将18通过相同的算法计算出一个hash值==>在hash表中找到对应的储存地址==>根据存储地址取得数据。
所以,每次查询时都要遍历hash表,直到找到对应的hash值,如(4),数据量大了之后,hash表也会变得庞大起来,性能下降,遍历耗时增加,如(5)。
三、R-Tree索引
R-Tree在MySQL很少使用,仅支持geometry数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种。
举个例子来说,比如你在为某商场做一个会员卡的系统。
这个系统有一个会员表 有下列字段:
会员编号 INT
会员姓名 VARCHAR(10)
会员身份证号码 VARCHAR(18)
会员电话 VARCHAR(10)
会员住址 VARCHAR(50)
会员备注信息 TEXT
那么这个 会员编号,作为主键,使用 PRIMARY
会员姓名 如果要建索引的话,那么就是普通的 INDEX
会员身份证号码 如果要建索引的话,那么可以选择 UNIQUE (唯一的,不允许重复)
会员备注信息 , 如果需要建索引的话,可以选择 FULLTEXT,全文搜索。
不过 FULLTEXT 用于搜索很长一篇文章的时候,效果最好。 用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
单列索引:即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。
组合索引:即一个索包含多个列,遵循”最左前缀“原则。
为了形象地对比两者,再建一个表:
在这10000条记录里面七上八下地分布了5条vc_Name="erquan"的记录,只不过city,age,school的组合各不相同。
来看这条T-SQL:
SELECT i_testID FROM myIndex WHERE vc_Name='erquan' AND vc_City='郑州' AND i_Age=25;首先考虑建单列索引:
在vc_Name列上建立了索引。执行T-SQL时,MYSQL很快将目标锁定在了vc_Name=erquan的5条记录上,取出来放到一中间结果集。在这个结果集里,先排除掉vc_City不等于"郑州"的记录,再排除i_Age不等于25的记录,最后筛选出唯一的符合条件的记录。
虽然在vc_Name上建立了索引,查询时MYSQL不用扫描整张表,效率有所提高,但离我们的要求还有一定的距离。同样的,在vc_City和i_Age分别建立的单列索引的效率相似。
为了进一步榨取MySQL的效率,就要考虑建立组合索引。就是将vc_Name,vc_City,i_Age建到一个索引里:
ALTER TABLE myIndex ADD INDEX name_city_age (vc_Name(10),vc_City,i_Age);--注意了,建表时,vc_Name长度为50,这里为什么用10呢?因为一般情况下名字的长度不会超过10,这样会加速索引查询速度,还会减少索引文件的大小,提高INSERT的更新速度。
执行T-SQL时,MySQL无须扫描任何记录就到找到唯一的记录!!
肯定有人要问了,如果分别在vc_Name,vc_City,i_Age上建立单列索引,让该表有3个单列索引,查询时和上述的组合索引效率一样吧?嘿嘿,大不一样,远远低于我们的组合索引~~虽然此时有了三个索引,但MySQL只能用到其中的那个它认为似乎是最有效率的单列索引。
建立这样的组合索引,其实是相当于分别建立了
vc_Name,vc_City,i_Age
vc_Name,vc_City
vc_Name这样的三个组合索引!为什么没有vc_City,i_Age等这样的组合索引呢?这是因为mysql组合索引"最左前缀"的结果。简单的理解就是只从最左面的开始组合。并不是只要包含这三列的查询都会用到该组合索引,下面的几个T-SQL会用到:
SELECT * FROM myIndex WHREE vc_Name="erquan" AND vc_City="郑州"
SELECT * FROM myIndex WHREE vc_Name="erquan"而下面几个则不会用到:
SELECT * FROM myIndex WHREE i_Age=20 AND vc_City="郑州"
SELECT * FROM myIndex WHREE vc_City="郑州"那么
SELECT * FROM myIndex WHREE vc_City="郑州" AND vc_Name="erquan" 这条sql会使用索引么?
答案是会的。
你可能会有疑问,这条语句并不符合最左匹配原则。这是由于查询优化器的存在,mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。所以,当然是我们能尽量的利用到索引时的查询顺序效率最高咯,所以mysql查询优化器会最终以这种顺序进行查询执行。
优化:在联合索引中将选择性最高的列放在索引最前面。
例如:在一个公司里以age 和gender为索引,显然age要放在前面,因为性别就两种选择男或女,选择性不如age。
可以使用explain检测索引是否被启用,如:
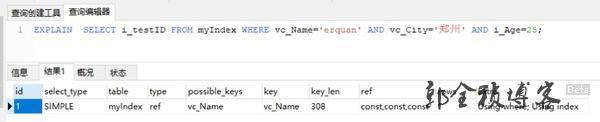
附:EXPLAIN列的解释
table:显示这一行的数据是关于哪张表的
type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL
type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL一般来说,得保证查询至少达到range级别,最好能达到ref。
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
rows:MYSQL认为必须检查的用来返回请求数据的行数
Extra:关于MYSQL如何解析查询的额外信息。这里可以看到的坏的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,结果是检索会很慢
索引好用但是同样不能滥用,下面说说创建索引的原则。
MySQL 索引设计原则:
(1)对于经常查询的字段,建议创建索引。
(2)索引不是越多越好,一个表如果有大量索引,不仅占用磁盘空间,而且会影响INSERT,DELETE,UPDATE等语句的性能。
(3)避免对经常更新的表进行过多的索引,因为当表中数据更改的同时,索引也会进行调整和更新,十分消耗系统资源。
(4)数据量小的表建议不要创建索引,数据量小时索引不仅起不到明显的优化效果,对于索引结构的维护反而消耗系统资源。
(5)不要在区分度低的字段建立索引。比如性别字段,只有 “男” 和 “女” ,建索引完全起不到优化效果。
(6)当唯一性是某字段本身的特征时,指定唯一索引能提高查询速度。
(7)在频繁进行跑排列分组(即进行 group by 或 order by操作)的列上建立索引,如果待排序有多个,可以在这些列上建立组合索引。
(8)尽量使用数据量少的索引,如果索引的值很长,那么查询的速度会受到影响。例如,对一个CHAR(100)类型的字段进行全文检索需要的时间肯定要比对CHAR(10)类型的字段需要的时间要多。
(9)尽量使用前缀来索引,如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和BLOG类型的字段,进行全文检索会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。
(10)删除不再使用或者很少使用的索引,表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
